1.请查看String.equals()方法的实现代码,注意学习其实现方法
将此字符串与指定的对象比较。当且仅当该参数不为 null,并且是与此对象表示相同字符序列的 String 对象时,结果才为 true。
2.请运行以下示例代码StringPool.java,查看其输出结果。如何解释这样的输出结果?从中你能总结出什么?
在字符串中“+”可以链接俩个字符串。
new String("Hello")==new String("Hello")相当于新建对象的比较,比较的是地址,因此是不相等的。
课后作业
1.字符加密
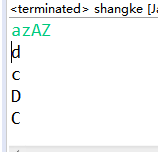
输入一段字符若字符在a-w,A-W之间。然后将阿斯克码值加三输出;若是x-z,X-Z将阿斯克吗值-23输出
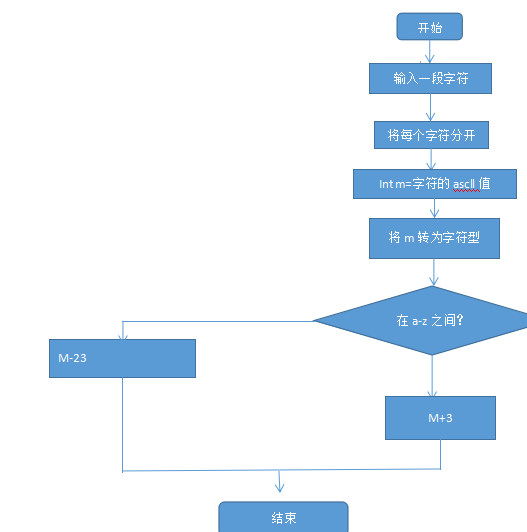
源代码:
package shangke;
import java.util.Scanner;
public class shangke {
public static void main(String[] args) {
// TODO Auto-generated method stub String s; Scanner in=new Scanner(System.in); s=in.next(); int i; for(i=0;i<s.length();i++) { char n,y; int m; n=s.charAt(i); m=n; if(('A'<=m&&m<'X')||('a'<=m&&m<'x')) { System.out.println((char)(m+3)); } else System.out.println((char)(m-23)); } //System.out.println(a);}
}
2.课后作业之字串加密、动手动脑之String.equals()方法、整理String类的Length()、charAt()、 getChars()、replace()、 toUpperCase()、 toLowerCase()、trim()、toCharArray()使用说明、阅读笔记
public char[] toCharArray()
- 将此字符串转换为一个新的字符数组。
-
- 返回:
- 一个新分配的字符数组,它的长度是此字符串的长度,它的内容被初始化为包含此字符串表示的字符序列。
public toUpperCase()
- 使用默认语言环境的规则将此
String中的所有字符都转换为大写。此方法等效于toUpperCase(Locale.getDefault())。注: 此方法与语言环境有关,如果用于应独立于语言环境解释的字符串,则可能生成不可预料的结果。示例有编程语言标识符、协议键、HTML 标记。例如,
"title".toUpperCase()在 Turkish(土耳其语)语言环境中返回"T?TLE",其中“?”是 LATIN CAPITAL LETTER I WITH DOT ABOVE 字符。对于与语言环境有关的字符,要获得正确的结果,请使用toUpperCase(Locale.ENGLISH)。 -
- 返回:
- 要转换为大写的
String。
- 要转换为大写的
public void getChars(int srcBegin, int srcEnd, char[] dst, int dstBegin)
- 将字符从此字符串复制到目标字符数组。
要复制的第一个字符位于索引
srcBegin处;要复制的最后一个字符位于索引srcEnd-1处(因此要复制的字符总数是srcEnd-srcBegin)。要复制到dst子数组的字符从索引dstBegin处开始,并结束于索引:dstbegin + (srcEnd-srcBegin) - 1
-
- 参数:
-
srcBegin- 字符串中要复制的第一个字符的索引。 -
srcEnd- 字符串中要复制的最后一个字符之后的索引。 -
dst- 目标数组。 -
dstBegin- 目标数组中的起始偏移量。
-
public trim()
- 返回字符串的副本,忽略前导空白和尾部空白。
如果此
String对象表示一个空字符序列,或者此String对象表示的字符序列的第一个和最后一个字符的代码都大于'\u0020'(空格字符),则返回对此String对象的引用。否则,若字符串中没有代码大于
'\u0020'的字符,则创建并返回一个表示空字符串的新String对象。否则,假定 k 为字符串中代码大于
'\u0020'的第一个字符的索引,m 为字符串中代码大于'\u0020'的最后一个字符的索引。创建一个新的String对象,它表示此字符串中从索引 k 处的字符开始,到索引 m 处的字符结束的子字符串,即this.substring(k, m+1)的结果。此方法可用于截去字符串开头和末尾的空白(如上所述)。
-
- 返回:
- 此字符串移除了前导和尾部空白的副本;如果没有前导和尾部空白,则返回此字符串。
public replace(char oldChar, char newChar)
- 返回一个新的字符串,它是通过用
newChar替换此字符串中出现的所有oldChar得到的。如果
oldChar在此String对象表示的字符序列中没有出现,则返回对此String对象的引用。否则,创建一个新的String对象,它所表示的字符序列除了所有的oldChar都被替换为newChar之外,与此String对象表示的字符序列相同。示例:
"mesquite in your cellar".replace('e', 'o') returns "mosquito in your collar" "the war of baronets".replace('r', 'y') returns "the way of bayonets" "sparring with a purple porpoise".replace('p', 't') returns "starring with a turtle tortoise" "JonL".replace('q', 'x') returns "JonL" (no change) -
- 参数:
-
oldChar- 原字符。 -
newChar- 新字符。 返回: - 一个从此字符串派生的字符串,它将此字符串中的所有
oldChar替代为newChar。
-
public toLowerCase()
- 使用默认语言环境的规则将此
String中的所有字符都转换为小写。这等效于调用toLowerCase(Locale.getDefault())。注: 此方法与语言环境有关,如果用于应独立于语言环境解释的字符串,则可能生成不可预料的结果。示例有编程语言标识符、协议键、HTML 标记。例如,
"TITLE".toLowerCase()在 Turkish(土耳其语)语言环境中返回"t?tle",其中“?”是 LATIN SMALL LETTER DOTLESS I 字符。对于与语言环境有关的字符,要获得正确的结果,请使用toLowerCase(Locale.ENGLISH)。 -
- 返回:
- 要转换为小写的
String。
- 要转换为小写的
public int length()
- 返回此字符串的长度。长度等于字符串中 Unicode 代码单元的数量。
-
- 指定者:
- 接口
中的length
- 接口
-
- 返回:
- 此对象表示的字符序列的长度。
public char charAt(int index)
- 返回指定索引处的
char值。索引范围为从0到length() - 1。 - 序列的第一个
char值位于索引0处,第二个位于索引1处,依此类推,这类似于数组索引。如果索引指定的
char值是代理项,则返回代理项值。 -
- 指定者:
- 接口
中的charAt
- 接口
-
- 参数:
-
index-char值的索引。 返回: - 此字符串指定索引处的
char值。第一个char值位于索引0处。
-